 One of the major problems in the field of deep learning is model opacity. This was a natural
consequence of ML being raised and nurtured in an industrial environment, where performance
superseded understanding. The deep learning revolution further exacerbated the problem of model
capacity, where it was found that instead of relying on the carefully hand-crafted features of
scientists, one could do away with Newton by simply adding more layers to the network.
Furthermore, the fact that complexity is often correlated with higher performance leads to black
boxes, representing an unrevealed tension between the values of the scientific method and the
design mode of machine learning models.
The opacity of deep learning models can be reduced via the application of various gradient
attribution methods. These methods can for example highlight the discriminant region of a
network trained on a binary classification task. To validate our application of these techniques
before aiming them at a serious research question, we applied them to a toy problem of
identifying sunspots from pores. In this case, we know that the distinguishing feature is the
presence of a penumbra (the intermediate grey region between the dark center and light
surroundings).
We discuss two methods here, the first requires measuring the sensitivity of the output with
regards to the final convolutional layers in a CNN, while the second works at the level of the
input directly via the application of a method from competitive game theory.
One of the major problems in the field of deep learning is model opacity. This was a natural
consequence of ML being raised and nurtured in an industrial environment, where performance
superseded understanding. The deep learning revolution further exacerbated the problem of model
capacity, where it was found that instead of relying on the carefully hand-crafted features of
scientists, one could do away with Newton by simply adding more layers to the network.
Furthermore, the fact that complexity is often correlated with higher performance leads to black
boxes, representing an unrevealed tension between the values of the scientific method and the
design mode of machine learning models.
The opacity of deep learning models can be reduced via the application of various gradient
attribution methods. These methods can for example highlight the discriminant region of a
network trained on a binary classification task. To validate our application of these techniques
before aiming them at a serious research question, we applied them to a toy problem of
identifying sunspots from pores. In this case, we know that the distinguishing feature is the
presence of a penumbra (the intermediate grey region between the dark center and light
surroundings).
We discuss two methods here, the first requires measuring the sensitivity of the output with
regards to the final convolutional layers in a CNN, while the second works at the level of the
input directly via the application of a method from competitive game theory.
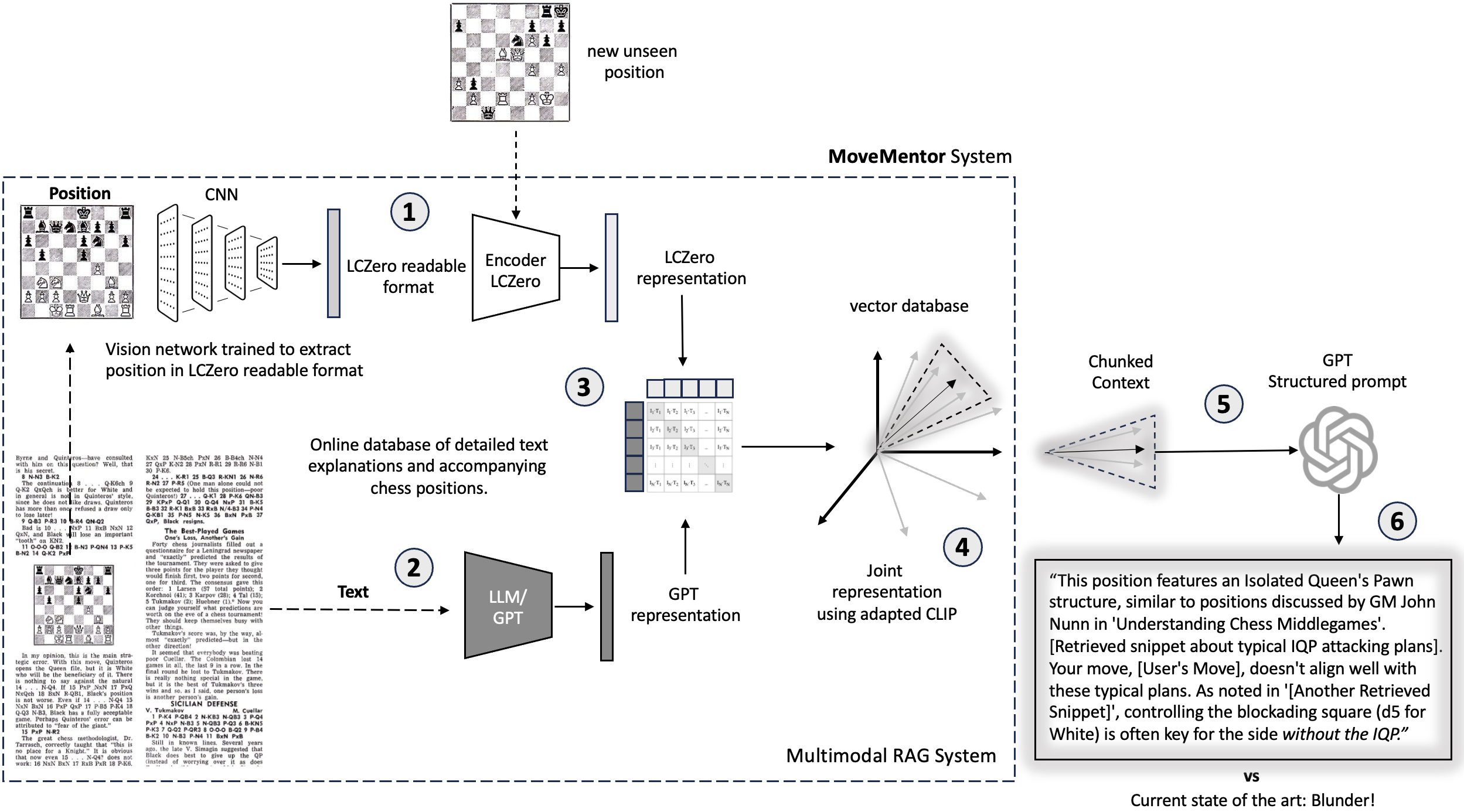
The first method called Gradient-weighted Class Activation Mapping (Grad-CAM) is derived from a
simpler implementation called CAM. The idea is that the most important spatial representation of
the input resides in the final convolutional layer before the dense layers. The spatial
information does not survive a pass through the dense layers since they are fully connected
(mixed). The authors of CAM noticed that if they fed the final convolutional layer directly into
a softmax, then the weights of the single dense layer can be used to directly evaluate the
importance of each pattern picked up by the final maps. A heatmap/salience map of the
discriminant region can then be obtained by projecting back a weighted linear sum of the final
feature maps, where the weights correspond to the weights of the softmax layer. This setup
represents a significant architecture constraint, namely that you have to go straight from the
convolutional layers into a softmax.
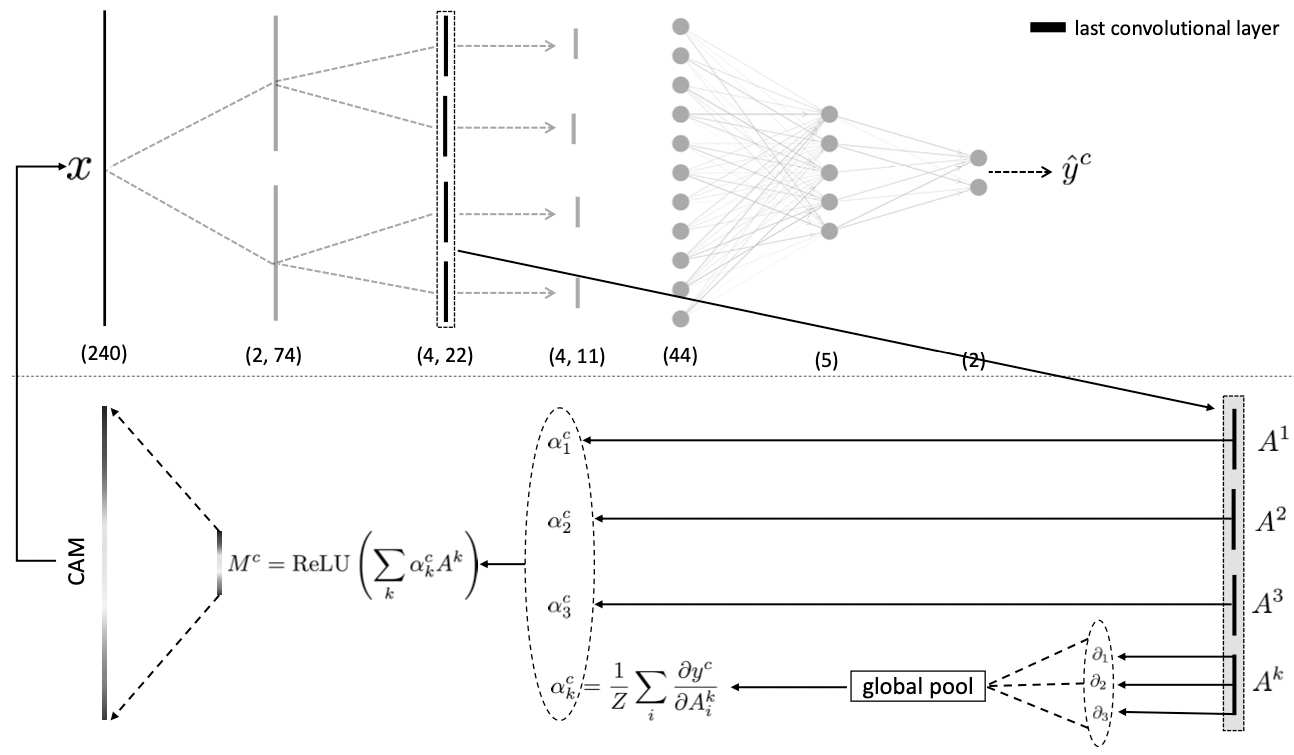
Grad-CAM also derives a heatmap from a linear sum of the final feature maps in the CNN, however,
the weights are derived as the sensitivity of the output prediction with respect to the final
feature maps. As can be seen in the above 1D illustration, the heatmap is given by $$ M =
\text{ReLU}\left(\sum_k \alpha_k A^k\right) $$ where the weights $\alpha_k$ for each on the
final convolutional feature maps $A^k$ are given by the pooled/average gradient of the output
with respect to the pixels in each feature map $$ \alpha^c_k = \frac{1}{Z}\sum_i\frac{\partial
y^c}{\partial A^k_i}. $$ Notice that the output is wrapped in a ReLU activation function so that
only positive gradients are considered, i.e., explanations that increase the prediction and
therefore correspond to the positive class. In this way, one can judge the importance of a
particular pattern from the input by simply monitoring the sensitivity of the output to first
order with respect to the final feature maps. This gradient trick represents a significant
improvement over CAM, and elevates the method to the class of gradient attribution methods,
where any convolutional architecture can be used. One important thing to note is that the
resolution of the explanation is at the same resolution as the final feature maps, which by
convention tends to shrink as you move to deeper layers in the network. This requires the final
saliency map to be extrapolated back to the original dimensionality. It also means that although
we have got rid of many restraints, the quality of the explanation is still tied to, and is
dependent on, the model's final architecture.
It would be desirable to have a model-agnostic method that does not rely on the special units of
a CNN. Such a method is called Expected-Gradients (EG) and it borrows ideas from competitive
game theory. It turns out that there exists a one-to-one mapping between the proper and fair
distribution of monetary rewards to individuals based on their contribution and the distribution
of a model's predictions amongst its inputs. The value that determines a player's contribution
to getting a final reward is called the Shapley value
$$ \phi_{\lambda}(\mathcal{F}_\Theta)=\sum_{S \subset N} \frac{(s-1) !(n-\mathrm{s}) !}{n
!}[\mathcal{F}_\Theta(S)-\mathcal{F}_\Theta(S-\lambda)], $$
where $\mathcal{F}_\Theta$ is some black box model or game (in this case it can be thought of as
the market), and $\lambda$ are the individual player of the game. This formula says that a
player's worth is the average difference between what would have been earned with and without
said player over all possible subsets/coalitions of players. The need to traverse all subsets is
due to the possible non-linear dependencies between performance and coalitions.
 We can replace the market $\mathcal{F}_\Theta$ with our black box ML model. The
people $\lambda$ become
individual pixels of our images, and the monetary reward can be mapped to the model's output
prediction in our binary classification pore/sunspot task. In other words, instead of fairly
distributing rewards, we use the Shapley value formalism to fairly distribute the model's
prediction, i.e., finding out which parts of the input is most responsible for said prediction.
We can replace the market $\mathcal{F}_\Theta$ with our black box ML model. The
people $\lambda$ become
individual pixels of our images, and the monetary reward can be mapped to the model's output
prediction in our binary classification pore/sunspot task. In other words, instead of fairly
distributing rewards, we use the Shapley value formalism to fairly distribute the model's
prediction, i.e., finding out which parts of the input is most responsible for said prediction.
The only complication is that it is not entirely clear how to implement the idea of a subset in
the case of a deep learning model. NNs required information to continually flow through all
their channels. One workaround is to feed in a baseline for missingness, such that the
expectation value of the baseline has a net zero effect on the final model output. Selecting a
tensor of zeros is a bad idea since zeros might be critical in images as they function as
borders and outlines. Another idea for missingness is to feed the network Gaussian noise.
Although this is an improvement, it comes with the assumption that each pixel is independent of
one another. This disregard for the possible wealth of interdependence between pixels will
result in an unfair estimation of contribution. To mitigate this, EG uses the dataset itself as
a baseline. The deep learning equivalence of the classically Shapley value formalism is given by
$$ \begin{align} \phi_\lambda|_\text{EG}
&=\int_{x^{\prime}}\Bigl(\left(x_\lambda-x_\lambda^{\prime}\right) \times \\ & \times
\int_{\alpha=0}^{1} \frac{\delta \mathcal{F}_\Theta
\left(x^{\prime}+\alpha\left(x-x^{\prime}\right)\right)}{\delta x_\lambda} d \alpha\Bigr)
p_{D}\left(x^{\prime}\right) d x^{\prime} \\ &\simeq\underset{x^{\prime} \sim D, \alpha \sim
U(0,1)}{\mathbb{E}}\left[\left(x_\lambda-x_\lambda^{\prime}\right) \frac{\delta
\mathcal{F}_\Theta\left(x^{\prime}+\alpha \times\left(x-x^{\prime}\right)\right)}{\delta
x_\lambda}\right], \end{align} $$
where $x$ is the target image in question. Here, we interpolate the image from a random baseline
image $x^\prime$ into the target image in question by progressing $\alpha = 0 \to 1$. During the
translation to the target image, the target features emerge and we monitor the accumulated
gradient of each pixel with respect to the model's output prediction. This is done for multiple
baselines such that on average, the gradients cancel after the expectation, and we have a fair
evaluation of how important each pixel is for the prediction. Notice that in order to form
pseudo subsets we have to pick up an additional integration factor.
We note that working directly at the resolution of the input data often results in non-smooth
saliency maps. EG is therefore often used as a differential prior during training, and a
smoothness condition requiring small changes between proximal pixels is invoked.
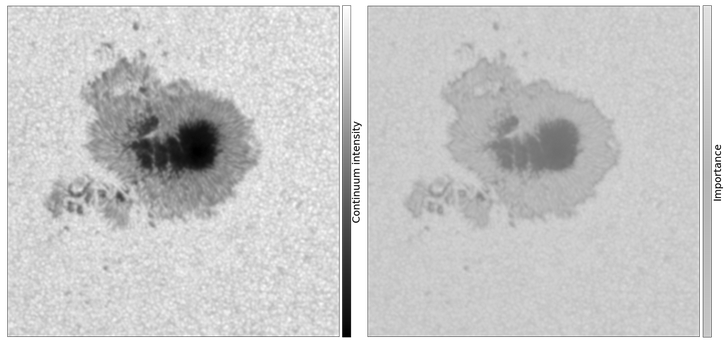
The results of Grad-CAM and Expected gradients were extremely complementary, with the above
image showing that indeed the network pooled its attention (orange colors) into the discriminant
structure, namely the penumbra. This is exactly what a human would base their decisions on when
trying to classify these images.
 The animation above illustrates how the model’s attention progressively converges on an important feature in the spectrogram of an IRIS observation during training. The model was trained for solar flare prediction. The top panel displays the training loss; as the model becomes more skillful, its attention narrows and highlights a critical pre-flare spectral signature in the IRIS spectrogram.
The animation above illustrates how the model’s attention progressively converges on an important feature in the spectrogram of an IRIS observation during training. The model was trained for solar flare prediction. The top panel displays the training loss; as the model becomes more skillful, its attention narrows and highlights a critical pre-flare spectral signature in the IRIS spectrogram.